Proteus Architecture

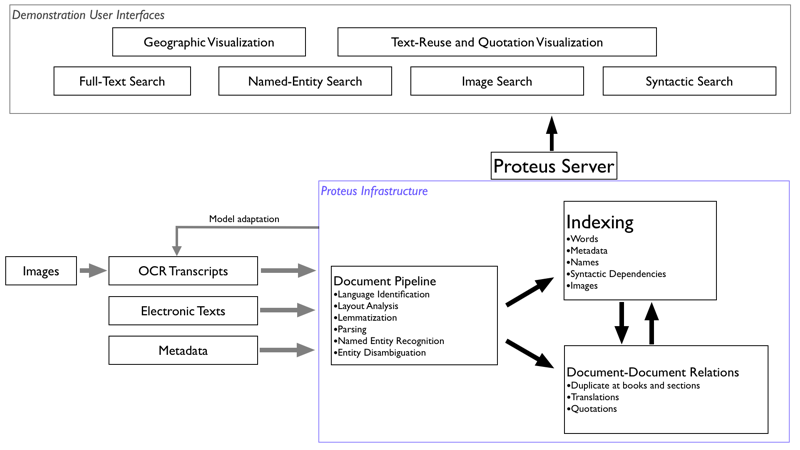
We propose, and have built an initial prototype of, a digital library architecture, called Proteus, that consists of a core architecture with a set of demonstration services built on top of it. We envisage that various communities would build their own interfaces on top of it to take advantage of the core information. In addition to the prototype search system, we show an example using Harvard’s Highbrow commentary visualizer to display the output of our automatic quotation detection. Proteus implements efficient annotation, linking, indexing, and querying of materials at many levels of granularity.
The core architecture comprises:
-
•a document processing pipeline, where natural language processing models automatically add annotations on documents’ structure and content. This process does layout analysis, determines whether there are pictures on the page and their location and size and parses each book, finds the language of the book from the content and whether it is badly recognized by an OCR. It also does named entity recognition and their disambiguation and lemmatization;
-
•an indexing system, which compiles document contents—the original text, user annotations, and machine-generated annotations from the document-processing and document-document relation subsystems—into a distributed set of indices for efficient retrieval; and
-
•a system for document-document relations, which infers implicit links between documents—for instance, that some documents are (partial) duplicates of each other and some contain quotations of others. This will also contain other relations such as which documents are topically related or translations of each other.
A Proteus server makes the data structures created by these processes available for services that help users search and explore the library.
We now describe some of the demonstration services we have built on top of the Proteus infrastructure.